
南京大学计算机系统基础实验 ICSPA(2023)PA 1 阶段 1
实验简介
PA 1 阶段 1 主要内容就是理解 NEMU 是如何编译运行,阅读 NEMU 的源代码,以及最后需要实现三个简单的指令。
在开始愉快的 PA 之旅之前
我选择了 riscv32 指令集。x86 和 mips 等到二周目再玩吧(如果还有二周目的话)。
安装 ccache
ccache 是一个编译缓存软件,能将我们编译后的内容缓存下来,在后续编译的时候如果没有发生变化,就可以使用缓存来加速编译。
使用 apt 安装完 ccache 之后,并不是直接就可以使用了,还需要使用 man 查看手册:

根据说明,在环境变量中添加 /usr/lib/ccache 就可以了。具体做法是,在 .bashrc 文件下添加:
|
|
开天辟地的篇章
对于这个思考题,我想现在就根据我学习过的知识尝试回答一下。当二周目的时候,我会保留这个回答,同时写一个新的回答在下面。
首先给出我的看法,我认为是不可以的。这是基于我学过的流水线 mips 处理器所给出的答案。
我们知道,计算机的核心部件就是 CPU,而寄存器是被包含在 CPU 里面的。在 CPU 内部,ALU 负责进行计算工作。而 ALU 能够访问的只有寄存器。
在 CPU 内部,有一个寄存器堆,ALU 可以任意地访问这些寄存器,从某些寄存器中取出操作数,将计算出来的结果存放在某个寄存器中。这些行为对应的阶段是 ID(译码)、EX(执行)、WB(写回)。
那么如果操作数位于内存呢?答案是,如果操作数在内存中,需要有一条专门的指令(load)来将数据从内存中读取到寄存器中。同理,也有一条专门的指令(write)将数据从寄存器写入到内存中。
所以,对于 CPU 来说,内存、缓存甚至硬盘,都属于“存储”。想要使用“存储”中的数据,必须要先将其读取到寄存器当中,才能进行操作。
从另外一个角度想,每一款 CPU 被设计出来,一定会对应某一套指令集,这套指令集里面就会有对寄存器的定义。寄存器和指令集都不会改变。但是我们却可以随意地更换内存,调整内存大小。这不就说明内存是属于 CPU 之外的吗?
RTFSC
这一章节一上来就要求我们读代码,并且没有任何目标,让人有点无从下手,不知道该做什么。
实际上这里只是告诉你项目的基本结构,以及该如何阅读源代码,然后让你理清整个程序大致的运行流程。并不需要真的一行一行地阅读代码。
我们只需要从 nemu_main.c 开始,将整个项目稍微看一遍就好了。也可以先往下看讲义,等到需要看代码的时候再看代码。
配置系统和项目构建
第一次读到一章节的时候,我的脑子感觉要爆炸了。不过静下心来好好理一理,还是能够理清楚的。
其实我一开始读到这一章节时候,读着读着读累了,就开始捣鼓 vscode。这时我发现我的 C/C++ 插件无法正常工作,具体表现为没有实时报错和代码补全。于是我打算配置一下我的 vscode 环境。
但我按照官方指南无论怎么配置,都没有任何反应。由于我之前写别的项目的时候,使用的是 clangd,于是我很自然地想到切换到 clangd,但当我切换到 clangd 之后发现,clangd 会给我报“无法找到头文件”的错误。
在这之前,我的解决办法都是创建一个 .vscode/ 文件夹,然后在里面创建一个 c_cpp_properties.json 文件来指定头文件所在的路径。但我一直有一个疑惑:为什么使用 make 等指令来编译的时候不会报错,而 vscode 会报错,需要指定头文件目录呢?
我突然想到,可能和 Makefile 文件有关系,说不定 Makefile 文件里就指明了头文件在哪里。答案是,我是对的,而且讲义其实也在讲这件事。
事实上,Makefile 告诉了 gcc 整个项目的结构是怎么样的,源代码放在哪里,编译需要的参数是什么等等。而讲义中提到的 Kconfig 就是用更友好的方式来让我们进行项目的配置,最后生成一个文件,然后让 Makefile 来引用。
配置系统 Kconfig
其实这部分内容就是把运行 make menuconfig 后程序自动执行的所有环节给展示了出来。
讲义中提到的 mconf 和 conf 其实都是根据项目编译出来的程序。当我们第一次执行 make menuconfig 的时候出现的编译指令就是用来编译它们的。
-
mconf 就是那个蓝底的 GUI,作用是来以可视化的方式给我们提供配置功能,他会读取
Kconfig文件的内容,生成对应的图形界面,然后在退出的时候将结果保存在.config文件里。 -
conf 没有图形界面,也不需要我们操作。它的作用是将
.config(也就是我们配置的内容),匹配Kconfig里的配置选项,然后生成一系列文件。这些文件有的是.h头文件,里面定义了常量,用来给项目代码引用;有的是.conf文件,用来给 Makefile 引用。
项目构建和 Makefile
这个项目的 Makefile 和我们在 PA0 中写的,以及学习时候遇到的 Makefile 有很大的不同。也是因为这个原因,vscode 的 Makefile 插件无法使用。
由于 Kconfig 的存在,以及项目比较大,因此根目录下的 Makefile 并不存放具体的编译细节,而只是定义了整个项目的框架,然后调用其他的 Makefile 文件。具体的编译规则等是存放在 scripts/ 文件夹下。这里面以 .mk 结尾的文件都是 Makefile。
阅读后可以发现,里面大量用到了 $(NEMU_HOME) 变量,这也是 PA0 里面为什么要配置系统环境变量的原因。
准备第一个客户程序
这一部分的内容主要是在讲 NEMU 启动的过程中进行的初始化工作。
NEMU 的启动过程其实就是模拟了真实硬件启动的过程。
首先,NEMU 中的 monitor 会将客户程序读入到固定的内存位置 RESET_VECTOR,这是定义在 include/memory/paddr.h 中的,这一步就是在模拟 BIOS 读取操作系统。
然后,NEMU 会使用代码来模拟计算机的硬件,例如用结构体模拟一些结构性强的存储部件(比如 cpu),用 char 数组模拟内存等。初始化寄存器的过程,其实就是初始化这些变量的值。
最后,NEMU 会将 cpu.pc 寄存器的值设置为客户程序的第一行。这一步就是模拟 BIOS 将 cpu 的控制权交给操作系统。
接下来客户程序就开始运行了。
下面是我对讲义里一些思考题的回答。
这是从软件工程的角度上考虑的。
从理论上来讲,将代码直接展开确实不影响代码的正确性,但是会极大地降低代码的可读性和可维护性。最显而易见的是,主函数的函数体必然会变得十分冗长。
使用函数调用的方法来编写代码,其实是软件工程当中分模块的思想。将不同模块的代码分开编写,可以使代码的结构更加清晰,更有利于多人协助开发。并且在测试的时候,也可以针对模块的函数单独进行测试。对于一个大项目来说,这是十分有必要的。
通过追溯参数的传递来源,最终可以发现这些参数都是从主函数的参数传过来的。
主函数的参数就是我们在启动程序的时候加上的参数。比如 mv a b,a 和 b 就是传给 mv 程序的两个参数。
主函数的参数列表中,第一个 int argc 代表参数的个数,第二个 char *argv[] 是一个字符串数组,分别指向各个参数的值。
运行第一个客户程序
到这里就开始正式地运行代码了。
运行代码的关键函数是 src/cpu/cpu-exec.c 中的 cpu_exec()。每调用一次这个函数,就是模拟 cpu 执行一行代码。
无限执行下去,直到程序结束。
通过 RTFCS 可以知道,参数的作用是执行多少步。而判断条件是 for(; n > 0; n--)。所以当传入的参数小于 0 的时候,就会无限执行下去
其实就是在编译的时候添加了一个 -DDEBUG 参数。
在执行完 make menuconfig 之后,可以发现生成了一个新的 .config 文件,并且旧的文件被重命名为 .config.old 来备份。
在这个新的 .config 文件中,多了一行:
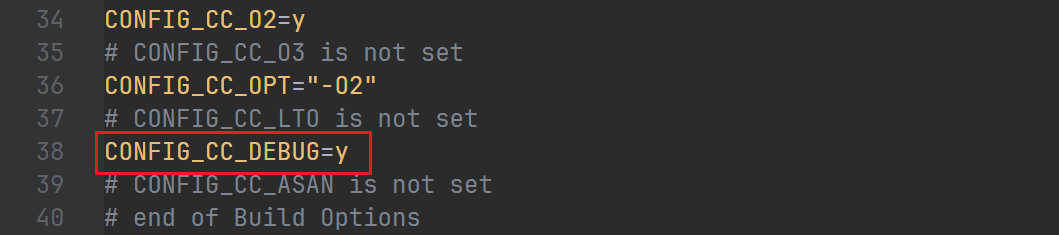
之后在执行 make 的时候,Makefile 就会读取这个配置然后自动添加参数了。
最后的这个退出,我们可以从 q 指令入手。
从主函数开始阅读代码,最终可以定位到 src/monitor/sdb/sdb.c 下的 sdb_mainloop() 函数的这一部分:
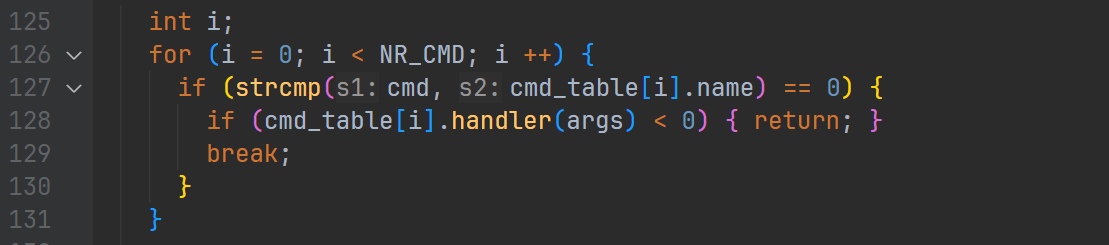
这里在做的事情是从 cmd_table 里尝试匹配指令,如果有匹配到的指令就调用对应的 handler() 函数并返回。当 handler() 函数的返回值为负数的时候就退出,然后整个程序就退出了。
找到 cmd_table:
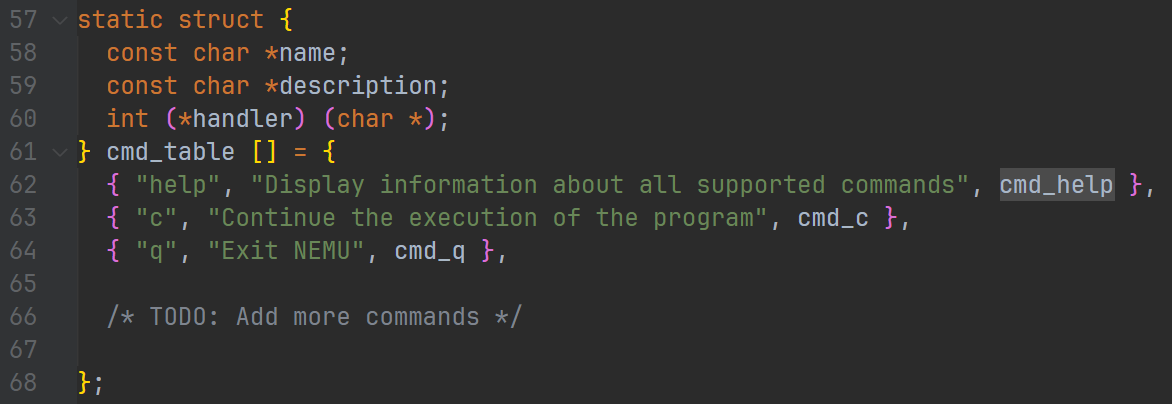
可以发现这里其实就是目前 NEMU 支持的指令。后续 PA 的内容就是在这里添加代码来支持更多指令。
找到 cmd_q() 函数,发现其直接返回了 -1,从而退出程序,符合我们的推断。
到这里感觉程序没什么问题,所以我们接着退回到主程序,继续往下看退出程序的过程。最终可以定位到 src/utils/state.c 文件的 is_exit_status_bad() 函数:

发现这里通过判断 nemu_state.state 的值来判断程序是否正常退出。
立刻想到,在处理 q 指令的时候,没有将 nemu_state.state 的值更新为 NEMU_QUIT,导致无法正确判断退出情况。
修改完即可正常退出。

基础设施:简易调试器
这一章的主要内容是让我们实现 PA 自带的一个简单调试器的部分功能。
这也是第一个需要写代码的章节。而至于每个功能需要在哪里添加代码,就需要好好阅读源代码了。
字符串处理
首先关于字符串的处理。如果我们看 PA 的代码会发现,PA 源代码使用的是 strtok() 这个函数来进行字符串的切割。
这个函数当然是很好用的,但是它每次调用只能切割一次,对于后面我们要实现的内存扫描等需要接受多个参数的指令来说,就需要调用很多次。而且它返回的只是第一个符合条件的地址,我们还需要用例如 atoi() 等额外的函数才能将其转换为数字。
所以在讲义中提到了另一个函数 sscanf()。他的用法和 scanf() 的用法完全一样,只是前面需要提供一个字符串的地址,相当于在一个字符串当中进行 scanf() 操作。它的返回值是成功读取的变量个数,我们可以通过这个来判断是否成功读取了所有的变量。
读取指令
添加功能的第一步当然是要让程序能够读取指令。
在上一个章节我们已经找到了指令是在哪里进行解析的,因此如果需要添加新的指令的话,就可以依葫芦画藤,按照已有的指令格式添加新的指令。
具体而言,添加一条指令需要在两个部分添加代码:
- 编写用于处理指令的函数;
- 在
cmd_table[]中添加指令格式并调用对应的处理函数;
单步执行
这个功能的实现确实很简单。只需要从参数中处理出来需要执行的步数,然后调用 cpu_exec() 函数来执行就好了。
需要额外注意的是参数的合法性,对于负数、非数字等情况需要进行判断,终止指令的执行并返回相关的提示信息。
打印寄存器
根据讲义的要求,我们在指令处理函数中只需要调用 isa_reg_display() 函数即可,具体的过程在该函数内实现。
阅读源代码可知,在 reg.h 文件中有一个宏定义 gpr(idx) 来获取寄存器,一个 reg_name() 来获取寄存器的名字。调用这两个函数/宏定义来输出就可以了。
不过我们可以发现,在 reg.c 中的 regs[] 存放了寄存器的名字。这么做的原因就是因为寄存器的结构是 ISA 相关的。不同的 ISA 的寄存器名字是不一样的,所以每个 ISA 都有一个自己的 reg.c 文件。
所以这里直接调用 regs[idx] 来输出名字也是可以的。不过在其他和 ISA 无关的代码中就必须使用 reg_name() 来获取寄存器的名字了。
扫描内存
首先我们可以使用 sscanf("%X") 来读取一个十六进制数,并且可以自动忽略十六进制的前导 0x。
阅读代码,可以发现和内存有关的代码是存放在 paddr.c 文件中的。而文件第一行代码 uint_t pmem[] 就是用来存放模拟器的内存数据了。
用来读取内存值的函数是 paddr_read() 。这个函数首先判断地址是否有效,然后调用 pmem_read() 来进一步读取内存数据。
在 pmem_read() 函数中,可以看到其调用了 host_read() 和 guest_to_host() 这两个宏/函数来读取数据。进一步分析可以知道,guest_to_host() 函数就是将原内存地址转换为模拟器模拟的内存数组的下标。而 host_read() 就是通过下标来读取数据。
分析到这里就足够了,调用对应的函数就可以实现扫描内存的功能。
判断输出的是否正确
那么如何判断功能实现的是否正确呢?讲义中说可以和内置客户程序的内容进行对比。
首先我们需要找到内置客户程序是在什么时候加载到内存中的,以及它的值是多少。
从主函数开始找,我们可以通过函数的注释来需要找的功能是否在该函数内,这样可以减少无用的查找。最终可以发现加载内置客户程序(也就是 built-in ./pics/image)是在 init.c 的 init_isa() 中。而程序就是 img[]:
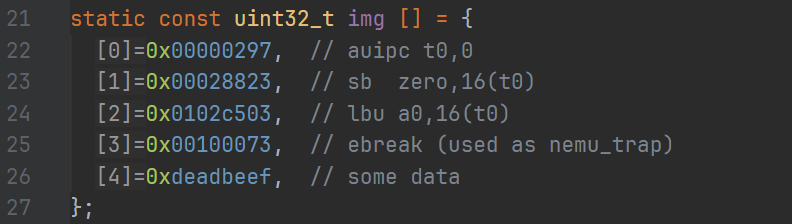
判断我们输出的和这里的值是否一致就可以了。
到此结束
PA 1 阶段 1 到此结束。